
聊聊CTR预估的中的深度学习
CTR预估
CTR预估一直以来都是工业界搜索、广告和推荐中的核心,而传统的LR模型(逻辑回归)几乎可以被称为CTR界的神算法,虽然他结构非常简单,但是他计算速度特别快,并且在加以特征工程师的修饰,一样可以拿到很好的效果。
但是这样的操作毕竟特征的选择会起比较重要的作用,如果遇到不同任务需要重新提取不同类型的特征。在2014年Facebook通过GBDT的生成LR特征的方式,取得了不错的效果。众所周知,GBDT中的策略树将会有一定的特征选择功能,因此该方式先原先(未经过太多特征工程的特征过一把GBDT),将GBDT的叶子节点作为特征继续输入到LR模型中,最终对目标的CTR值进行预测。
除特征工程外,LR的另一个缺陷就是对于高阶的表达能力不足,从这两个出发点,结合公司中手头的一些工作,整了下最近比较经典的Paper来说说深度学习在CTR预估中的一些方法,主要有:FNN、PNN、Wide&Deep、Deep&Cross、DeepFm、NFM.
FNN
上海交大张伟楠老师利用FM做特征Embedding,然后在上面叠加nn,提出了FNN模型。
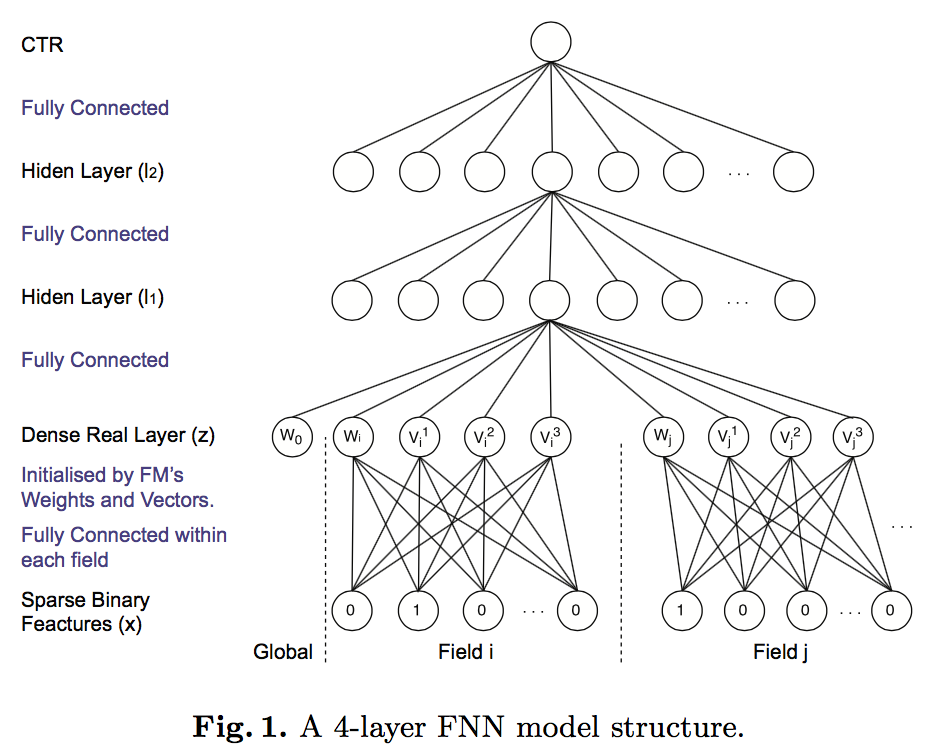
其实模型架构图还是蛮清晰的,看懂了FM那一层之后就很明了了:
- 输入的是各种稀疏特征(可以是最简单的各种id)
- 接下来将会经过一个
已训练的FM层,直接取到FM模型中对于特征的隐向量 - 通过隐向量可以构造出
NN的输入层z:$z = (w_0,z_1,z_2,…,z_n)$,而$z_i=(w_i,v_i^1,v_i^2,…v_i^K)$,其中$w_i$为FM中的一阶权重,$v_i$为对应特征的隐向量 - 再接下来就是堆一个
NN层来计算最终的目标值了。
FNN的最大优势就是不需要再去做特征工程了,其特征由FM的隐向量构建得到。同时其缺点就是需要pre-train才能让这个FNN给跑起来.
PNN
2016年,张伟楠老师他们又提出了一种名为PNN的模型,对Embedding向量做innner/outer product(其实就是对原来的FNN模型进行改吧改吧)。
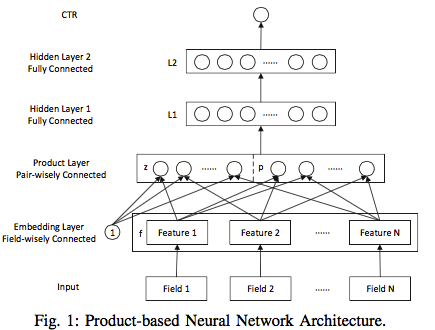
其中(bottom-top方向):
- 其中第一层是输入的离散特征
Field N - 第二层是对离散特征的
Embedding(这儿Embedding的方式有很多种,最经典的就是TF的lookup_table) - 重点在第三层,就是模型的创新点
Product Layer,这里分两部分,一部分是$z$,他是保持了原有Embedding向量的数据,另一部分是$p$,主要对上一层的向量数据进行pairwise feature interaction,也就是做product的工作 - 接下来又是继续走一波
NN网络 - 最后对点击率进行预估计算
上面的是整个PNN的模型架构,而根据$p$中可选Inner Product和Outer Product的两种方式提出IPNN和OPNN这两个模型,这两模型中$z$是一样的,先来看一下$z$:
$$l_z =(l_z^1,l_z^2,…,l_z^n,…,l_z^{D1})$$
而
$$l_z^n = W_z^n \odot z_n = \sum_j^M (W_z^n)_{j} f_{n,j}$$
这里的$f_i$为第$i$个特征的
Embedding
因此可以看出$l_z$其实只是对原有的Embedding做了一层转换
在$p$部分:
$$l_p =(l_p^1,l_p^2,…,l_p^n,…,l_p^{D1})$$
并且$$p={p_{i,j}} ,i=1…N,j=1..N$$
其中$p_{i,j} = g(f_i,f_j)$
$g$就是可以做Inner Product和Outer Product
这里再细节的东西就不贴了,感觉Paper里的符号的上下标有点乱(当然也有可能是我没完全看明白-_-),其实PNN里面的主要贡献就是在Embedding的基础上再多做一些Pairwise Product的操作增强高阶/非线性效果。
Wide&Deep
相比对FNN和PNN,Google在2016年提出来的Wide&Deep模型更加有名气和通用化一些,顾名思义,整个模型将分为Wide和Deep两个部分:
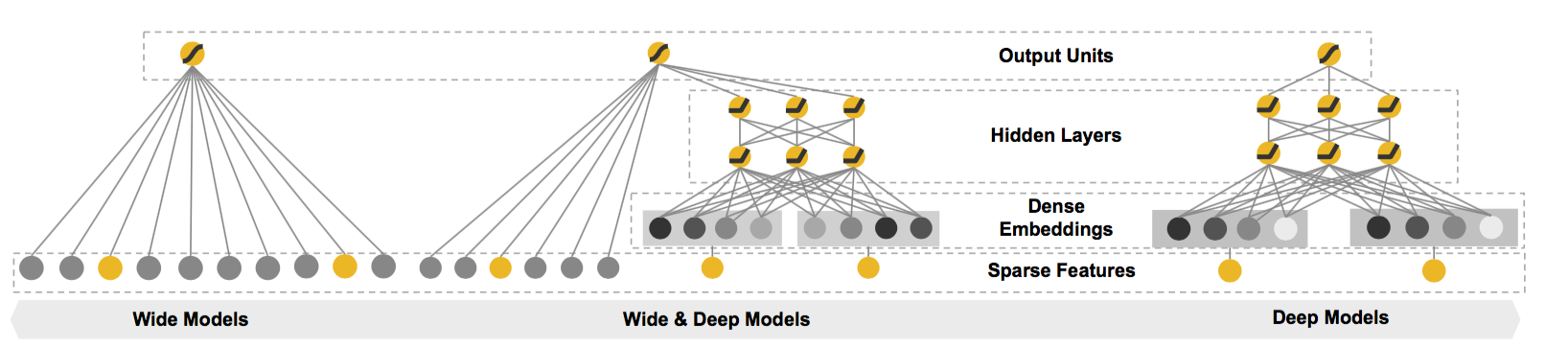
左边的Wide是传统的大规模特征+线性模型(也就是经典的LR模型),右边的Deep是一个DNN模型,而中间的Wide&Deep把两个模型在最后一层做了组合。原文中其实是将两个模型的输出求和:
$$P(Y=1|x) = \sigma(W_{wide}^T[x,\phi(x)] + W_{deep}^T \alpha^{(lf)}+b)$$
很明显是一个分治的思想,Wide负责处理大规模离散特征,Deep负责处理连续特征,各自发挥自己的优势。再按文章的意思就是:
Wide可以达到Memorization功能,从训练数据中学习已经出现过的共现和相关性。Deep可以有Generalization:对于没有出现过的数据,需要从数据中学习到抽象的概念,也就是泛化性。
Wide&Deep模型简单,扩展性更加强,而且运行效率上也比较可控,因此在实际业务中使用非常广泛,并且原生的TF也还提供了Wide&Deep的接口:https://www.tensorflow.org/tutorials/wide_and_deep
另外在DeepFM中有一个图对比FNN、PNN、Wide&Deep的区别,非常的清晰:
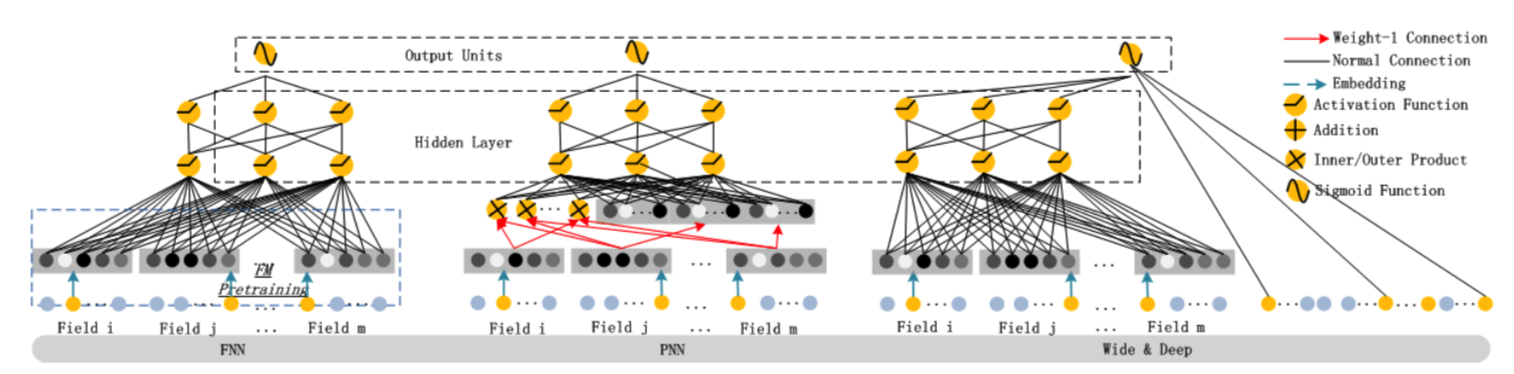
Deep&Cross
Wide&Deep虽然经典,但是仍旧么有解决特征组合问题,特征组合算法在FM系列的深度学习中也已经有不少研究:DeepFm、NFM.,Google在2017年又提出了一种名为Deep&Cross的CTR预估算法(也简称DCN),可以用级联的方式来深度的提取高阶的特征,同样先来看下模型的架构:
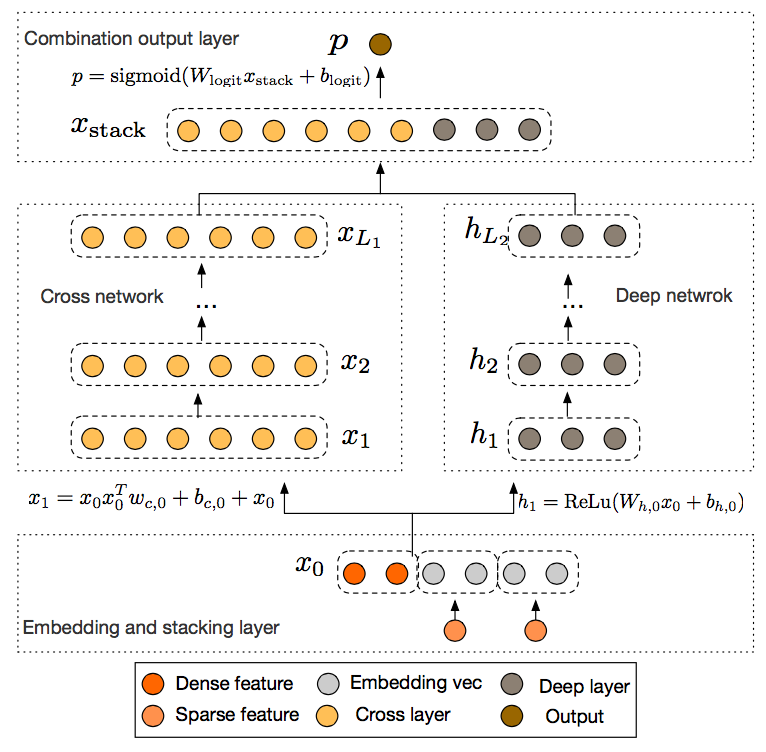
如上图:
DCN模型的输入基本为连续特征(Dense Feature)和id类的离散特征(Sparse Feature),同时将会离线特征处理成embedding特征,这样就可以通过理解为模型的输入是一个连续的向量$x_0$- 接下来模型分为两部分:
- 右侧部分是传统的DNN模型,其中每个全连接层都使用
RELU激活函数, 把输入特征通过多个全连接层之后特征变得更加高阶:$$h_i=\text{ReLu}(w_{h,i}x_{i-1}+b_{h,i})$$ - 左侧部分则是DCN的核心
Cross层,每一层的特征都由其上一层的特征进行交叉组合,并且会吧上一层的原始特征重新加回来。这样既能做特征组合,又能保留低阶原始特征,而且还随着Cross层的增加,是可以生成任意高阶的交叉组合特征$$x_{l+1} = x_0x_l^Tw_l+b_l+x_l = f(x_l,w_l,b_l)+x_l$$
- 右侧部分是传统的DNN模型,其中每个全连接层都使用
- 最终会将
DNN模型和Cross模型输出的向量进行concat起来之后过一把LR进行点击率预测。
其中Cross的特征组合层与FM相比,可以理解为FM只能做到两阶的特征组合(因为FM是嵌套方式的,如果是多阶的特征是指数上升的),而Cross里面的可以完成任意多阶的组合,阶数与Cross的深度一致,并且其参数复杂度与阶数是线性关系$$d \times L_c \times 2$$
$d$为输入向量的大小,$L_c$为
Cross的深度
总结
上面几种深度学习模型基本是在一个固有的DNN结构上,在输入层加东西或者在隔壁加额外层来结合。FNN和PNN算法在特征组合与深度学习的结合上都给出了不少启发,但是毕竟Google出品,必属精品,Wide&Deep无疑是使用更加广泛,当然在目前机器资源越来越好的情况下,也将会有更多更加复杂的深度模型将会取尝试。
同时也有经验表明,在不断上各种复杂模型的前提下,CTR预估的效果还是会不断的提升。
参考
[1]. He, Xinran, et al. “Practical lessons from predicting clicks on ads at facebook.” Proceedings of the Eighth International Workshop on Data Mining for Online Advertising. ACM, 2014.
[2]. Zhang, Weinan, Tianming Du, and Jun Wang. “Deep learning over multi-field categorical data.” European conference on information retrieval. Springer, Cham, 2016.
[3]. Qu, Yanru, et al. “Product-based neural networks for user response prediction.” Data Mining (ICDM), 2016 IEEE 16th International Conference on. IEEE, 2016.
[4]. Cheng, Heng-Tze, et al. “Wide & deep learning for recommender systems.” Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 2016.
[5]. Wang, Ruoxi, et al. “Deep & Cross Network for Ad Click Predictions.” arXiv preprint arXiv:1708.05123 (2017).
